MOROCCO¶
MOdel ResOurCe COnsumption evaluation project
MOROCCO project is aimed to evaluate Russian SuperGLUE models performance: inference speed, GPU RAM usage.
We highly welcome leaderboard participants to move from static text submissions with predictions to public repositories for their models and reproducible Docker-containers.
This page contains general description of the project. For public docker images and technical documentation please see Marocco github page. All credits go to @kuk
Models¶
At the moment, the project team is measuring the performance of all publicly available models: rubert, rubert-conversational, bert-multilingual, rugpt3-small, rugpt3-medium, rugpt3-small, rugpt3-large.
To add your model to the performance leaderboard: 1) create a docker container according to the example 2) specify the public URL of the model and the container code to run it when submitting the results.
RuBert¶
Monolingual Russian BERT (Bidirectional Encoder Representations from Transformers) in DeepPavlov realization: cased, 12-layer, 768-hidden, 12-heads, 180M parameters
RuBERT was trained on the Russian part of Wikipedia and news data. The training data was used to build vocabulary of Russian subtokens and then multilingual version of BERT-base was used for the initialization for RuBERT model
- Docs: http://docs.deeppavlov.ai/en/master/features/models/bert.html
- Repository: https://github.com/deepmipt/DeepPavlov/blob/master/docs/features/models/bert.rst
- HuggingFace: https://huggingface.co/DeepPavlov/rubert-base-cased
RuBert Conversational¶
BERT in DeepPavlov realization: Russian, cased, 12-layer, 768-hidden, 12-heads, 180M parameters
Conversational RuBERT was trained on OpenSubtitles, Dirty, Pikabu, and Social Media segment of Taiga corpus. New vocabulary ws assembled for Conversational RuBERT model on this data; the model was initialized with RuBERT weights.
- Docs: http://docs.deeppavlov.ai/en/master/features/models/bert.html
- Repository: https://github.com/deepmipt/DeepPavlov/blob/master/docs/features/models/bert.rst
- HuggingFace: https://huggingface.co/DeepPavlov/rubert-base-cased-conversational
Bert multilingual¶
Classic mBert
- Docs: https://github.com/google-research/bert
- Repository: https://github.com/google-research/bert#pre-trained-models
- HuggingFace: https://huggingface.co/bert-base-multilingual-cased
RuGPT3 Family¶
Russian GPT3 models trained with 2048 context length including rugpt3-small, rugpt3-medium, rugpt3-large
- Docs: https://github.com/sberbank-ai/ru-gpts
- Repository: https://github.com/sberbank-ai/ru-gpts
- HuggingFace: https://huggingface.co/sberbank-ai
Performance¶
GPU RAM¶
To measure model GPU RAM usage we run a container with a single record as input, measure maximum GPU RAM consumption, repeat procedure 5 times, take median value. rubert, rubert-conversational, bert-multilingual, rugpt3-small have approximately the same GPU RAM usage. rugpt3-medium is ~2 times larger than rugpt3-small, rugpt3-large is ~3 times larger.
| danetqa | muserc | parus | rcb | rucos | russe | rwsd | terra | lidirus | |
|---|---|---|---|---|---|---|---|---|---|
| rubert | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.39 | 2.39 | 2.39 |
| rubert-conversational | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.39 | 2.39 | 2.39 |
| bert-multilingual | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.40 | 2.39 | 2.39 |
| rugpt3-small | 2.38 | 2.38 | 2.36 | 2.37 | 2.38 | 2.36 | 2.36 | 2.37 | 2.36 |
| rugpt3-medium | 4.41 | 4.38 | 4.39 | 4.39 | 4.38 | 4.38 | 4.41 | 4.39 | 4.39 |
| rugpt3-large | 7.49 | 7.49 | 7.50 | 7.50 | 7.49 | 7.49 | 7.51 | 7.50 | 7.50 |
GPU RAM usage, GB
Inference speed¶
To measure inference speed we run a container with 2000 records as input, with batch size 32. On all tasks batch size 32 utilizes GPU almost at 100%. To estimate initialization time we run a container with input of size 1. Inference speed is (input size = 2000) / (total time - initialization time). We repeat procedure 5 times, take median value.
| danetqa | muserc | parus | rcb | rucos | russe | rwsd | terra | lidirus | |
|---|---|---|---|---|---|---|---|---|---|
| rubert | 118 | 4 | 1070 | 295 | 9 | 226 | 102 | 297 | 165 |
| rubert-conversational | 103 | 4 | 718 | 289 | 8 | 225 | 101 | 302 | 171 |
| bert-multilingual | 90 | 4 | 451 | 194 | 7 | 164 | 85 | 195 | 136 |
| rugpt3-small | 97 | 4 | 872 | 289 | 8 | 163 | 105 | 319 | 176 |
| rugpt3-medium | 45 | 2 | 270 | 102 | 3 | 106 | 70 | 111 | 106 |
| rugpt3-large | 27 | 1 | 137 | 53 | 2 | 75 | 49 | 61 | 69 |
Inference speed, records per second
General evaluation¶
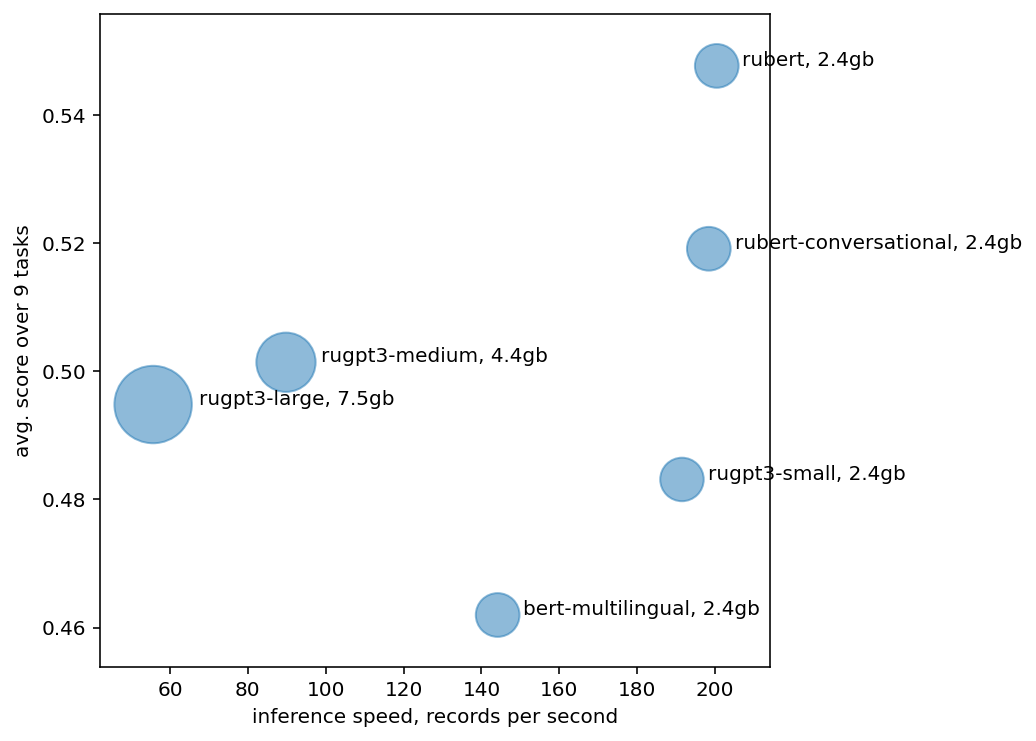
Each disc corresponds to baseline model, disc size is proportional to GPU RAM usage. By X axis there is model inference speed in records per second, by Y axis model score averaged by 9 Russian SuperGLUE tasks.
- Smaller models have higher inference speed.
rugpt3-smallprocesses ~200 records per second whilerugpt3-large— ~60 records/second. bert-multilingualis a bit slower thenrubert*due to worse Russian tokenizer.bert-multilingualsplits text into more tokens, has to process larger batches.- It is common that larger models show higher score but in our case
rugpt3-medium,rugpt3-largeperform worse then smallerrubert*models. rugpt3-largehas more parameters thenrugpt3-mediumbut is currently trained for less time and has lower score.