MOROCCO¶
MOdel ResOurCe COnsumption Оценка использования ресурсов NLP-моделями
Проект MOROCCO направлен на оценку производительности российских моделей SuperGLUE: скорости инференса, использования оперативной памяти GPU.
Призываем всех участников основного лидерборда Russian SuperGLUE переходить от представления статических json'ов с ответами к публичным репозиториям для своих моделей и воспроизводимых результатов в Docker-контейнерах.
На этой странице вы найдете описание проекта. Общедоступные докер-контейнеры с моделями и техническую документацию см. на странице Marocco на github. Проект основан @kuk
Модели¶
В проекте измеряется производительность опен-сорс моделей:rubert, rubert-conversational, bert-multilingual, rugpt3-small, rugpt3-medium, rugpt3-small, rugpt3-large.
Чтобы добавить свою модель на лидерборд производительности: 1) создайте докер-контейнер в соответствии с примером 2) укажите общедоступный URL-адрес модели и код контейнера для ее запуска при отправке результатов.
RuBert¶
Русскоязычный BERT в реализации DeepPavlov: архитектура Bidirectional Encoder Representations from Transformers: cased, 12-слоев, 768-скрытых, 12-голов, 180M параметров
RuBERT обучался на русскоязычной части Википедии и новостных данных. Эти данные использовались для создания словаря русских субтокенов, при этом в качестве инициализации для RuBERT была взята многоязычная версия BERT-base
- Документация: http://docs.deeppavlov.ai/en/master/features/models/bert.html
- Репозиторий: https://github.com/deepmipt/DeepPavlov/blob/master/docs/features/models/bert.rst
- HuggingFace: https://huggingface.co/DeepPavlov/rubert-base-cased
RuBert Conversational¶
BERT в реализации DeepPavlov: Russian, cased, 12-слоев, 768-скрытых, 12-голов, 180M параметров
Conversational RuBERT обучался на OpenSubtitles, Dirty, Pikabu, и сегменте Social Media из корпуса Taiga. На этих данных был собран новый словарь токенов для модели Conversational RuBERT, модель была инициализирована весами RuBERT.
- Документация: http://docs.deeppavlov.ai/en/master/features/models/bert.html
- Репозиторий: https://github.com/deepmipt/DeepPavlov/blob/master/docs/features/models/bert.rst
- HuggingFace: https://huggingface.co/DeepPavlov/rubert-base-cased-conversational
Bert multilingual¶
Классический mBert
- Документация: https://github.com/google-research/bert
- Репозиторий: https://github.com/google-research/bert#pre-trained-models
- HuggingFace: https://huggingface.co/bert-base-multilingual-cased
RuGPT3 Family¶
Русскоязычные GPT3 модели, обученные с контекстом 2048 токенов, включая rugpt3-small (125 млн параметров), rugpt3-medium (350 млн параметров), rugpt3-large (760 млн параметров)
- Документация: https://github.com/sberbank-ai/ru-gpts
- Репозиторий: https://github.com/sberbank-ai/ru-gpts
- HuggingFace: https://huggingface.co/sberbank-ai
Производительность¶
GPU RAM¶
Чтобы измерить использование GPU RAM моделью, мы запускаем контейнер с одной записью в качестве входных данных, измеряем максимальное потребление ОЗУ графического процессора, повторяем процедуру 5 раз, берем медианное значение. rubert, rubert-conversational, bert-multilingual, rugpt3-small имеют примерно одинаковое потребление GPU RAM. rugpt3-medium в ~2 раза больше, чем rugpt3-small, rugpt3-large в ~3 раза больше. rubert, rubert-conversational, bert-multilingual, rugpt3-small имеют примерно одинаковое потребление GPU RAM. rugpt3-medium в ~2 раза больше, чем rugpt3-small, rugpt3-large в ~3 раза больше.
| danetqa | muserc | parus | rcb | rucos | russe | rwsd | terra | lidirus | |
|---|---|---|---|---|---|---|---|---|---|
| rubert | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.39 | 2.39 | 2.39 |
| rubert-conversational | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.39 | 2.39 | 2.39 |
| bert-multilingual | 2.40 | 2.40 | 2.39 | 2.39 | 2.40 | 2.39 | 2.40 | 2.39 | 2.39 |
| rugpt3-small | 2.38 | 2.38 | 2.36 | 2.37 | 2.38 | 2.36 | 2.36 | 2.37 | 2.36 |
| rugpt3-medium | 4.41 | 4.38 | 4.39 | 4.39 | 4.38 | 4.38 | 4.41 | 4.39 | 4.39 |
| rugpt3-large | 7.49 | 7.49 | 7.50 | 7.50 | 7.49 | 7.49 | 7.51 | 7.50 | 7.50 |
GPU RAM usage, GB
Время инференса¶
Для измерения скорости инференса мы запускаем контейнер с 2000 записями в качестве входных данных с размером батча 32. Во всех задачах размер батча 32 использует GPU почти на 100%. Чтобы оценить время инициализации, мы запускаем контейнер с инпутом размера 1. Скорость инференса равна (размер инпута = 2000) / (общее время - время инициализации). Повторяем процедуру 5 раз, берем медианное значение.
| danetqa | muserc | parus | rcb | rucos | russe | rwsd | terra | lidirus | |
|---|---|---|---|---|---|---|---|---|---|
| rubert | 118 | 4 | 1070 | 295 | 9 | 226 | 102 | 297 | 165 |
| rubert-conversational | 103 | 4 | 718 | 289 | 8 | 225 | 101 | 302 | 171 |
| bert-multilingual | 90 | 4 | 451 | 194 | 7 | 164 | 85 | 195 | 136 |
| rugpt3-small | 97 | 4 | 872 | 289 | 8 | 163 | 105 | 319 | 176 |
| rugpt3-medium | 45 | 2 | 270 | 102 | 3 | 106 | 70 | 111 | 106 |
| rugpt3-large | 27 | 1 | 137 | 53 | 2 | 75 | 49 | 61 | 69 |
Время инференса, примеров в секунду
Общая оценка¶
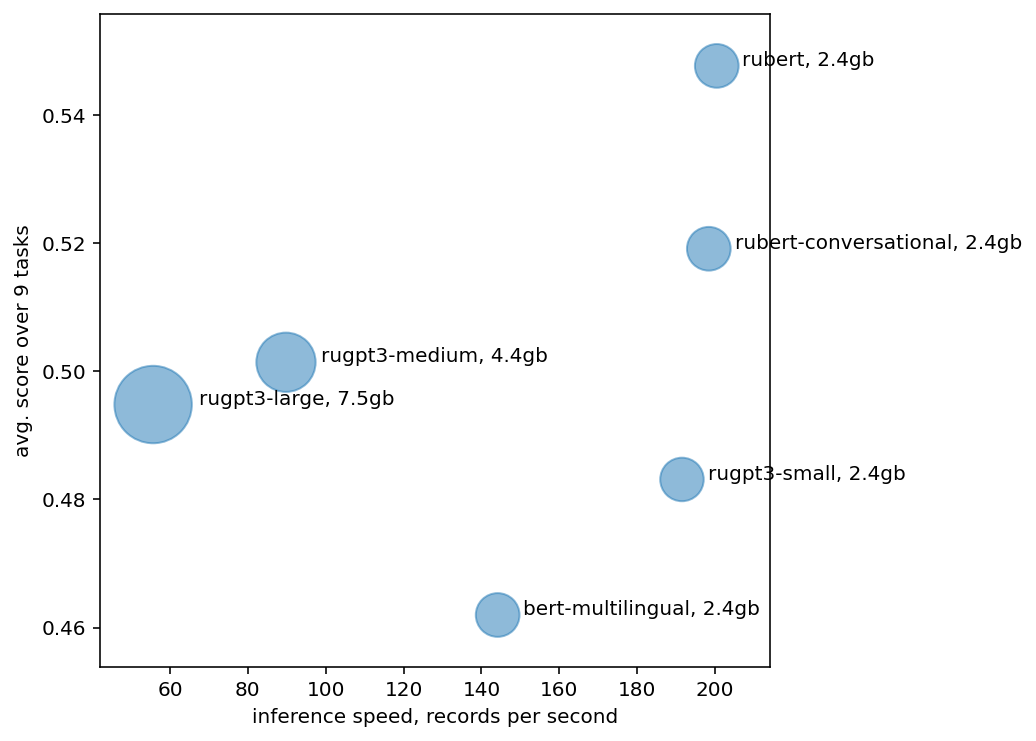
Каждый диск на диаграмме ниже соответствует базовой модели из списка, площадь диска пропорционален использованию GPU RAM. по оси X - скорость инференса модели в записях в секунду, по оси Y - средняя оценка модели по 9 задачам Russian SuperGLUE.
- У меньших моделей более высокая скорость инференса.
rugpt3-smallобрабатывает ~200 примеров в секунду, тогда какrugpt3-large— ~60 примеров/сек. bert-multilingualчуть медленнее чемrubert*из-за худшего русскоязычного токенизатора.bert-multilingualразбивает тексты на большее число токенов, и ему требуется обработать более крупные батчи.- Обычно бОльшие модели показывают более высокие результаты, однако в текущем случае модели
rugpt3-medium,rugpt3-largeработают чуть хуже чем меньшиеrubert*модели. rugpt3-largeбольшее число параметров, чем уrugpt3-mediumпри этом она обучена за меньшее время и имеет более низкие результаты.